启用 Prometheus Federator
要求
默认情况下,Prometheus Federator 已配置并旨在与 rancher-monitoring 一起部署。rancher-monitoring 同时部署了 Prometheus Operator 和 Cluster Prometheus,每个项目监控堆栈(Project Monitoring Stack)默认会联合命名空间范围的指标。
有关安装 rancher-monitoring 的说明,请参阅此页面。
默认配置与你的 rancher-monitoring 堆栈是兼容的。但是,为了提高集群中 Prometheus Federator 的安全性和可用性,我们建议对 rancher-monitoring 进行以下额外的配置:
- 确保 cattle-monitoring-system 命名空间位于 System 项目中
- 将 rancher-monitoring 配置为仅监视 Helm Chart 创建的资源
- 提高 Cluster Prometheus 的 CPU/内存限制
确保 cattle-monitoring-system 命名空间位于 System 项目中(或者位于一个锁定并能访问集群中其他项目的项目中)
Prometheus Operator 的安全模型有一定的要求,即希望部署它的命名空间(例如,cattle-monitoring-system)对除集群管理员之外的任何用户都只有有限的访问权限,从而避免通过 Pod 内执行(例如正在执行的 Helm 操作的 Job)来提升权限。此外,如果将 Prometheus Federator 和所有 Project Prometheus 堆栈都部署到 System 项目中,即使网络策略是通过项目网络隔离定义的,每个 Project Prometheus 都依然能够在所有项目中抓取工作负载。它还为项目所有者、项目成员和其他用户提供有限的访问权限,从而确保这些用户无法访问他们不应访问的数据(例如,在 pod 中执行,在项目外部抓取命名空间数据等)。
打开
System项目以检查你的命名空间:在 Rancher UI 中单击 Cluster > Projects/Namespaces。这将显示
System项目中的所有命名空间: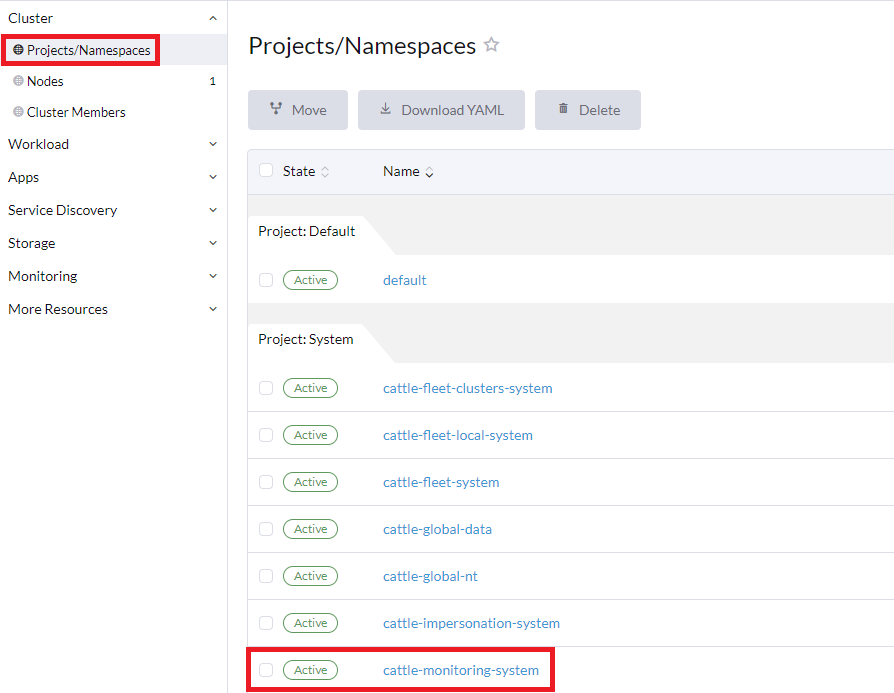
如果你在
cattle-monitoring-system命名空间中已经安装了一个 Monitoring V2,但该命名空间不在System项目中,你可以将cattle- monitoring-system命名空间移动到System项目或另一个访问受限的项目中。为此,你有以下两种方法:将命名空间拖放到
System项目。选择命名空间右侧的 ⋮,点击 Move,然后从 Target Project 下拉列表中选择
System: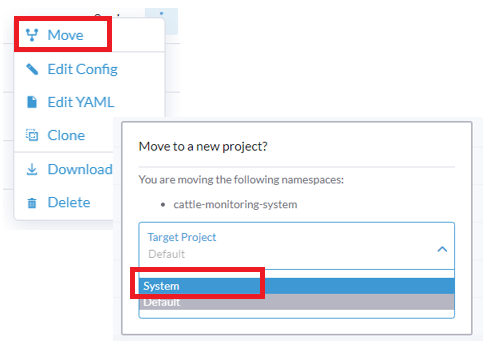
将 rancher-monitoring 配置为仅监视 Helm Chart 创建的资源
每个项目监控堆栈都会监视其他命名空间并收集其他自定义工作负载指标或仪表板。因此,我们建议在所有选择器上配置以下设置,以确保 Cluster Prometheus 堆栈仅监控由 Helm Chart 创建的资源:
matchLabels:
release: "rancher-monitoring"
建议为以下选择器字段赋予此值:
.Values.alertmanager.alertmanagerSpec.alertmanagerConfigSelector.Values.prometheus.prometheusSpec.serviceMonitorSelector.Values.prometheus.prometheusSpec.podMonitorSelector.Values.prometheus.prometheusSpec.ruleSelector.Values.prometheus.prometheusSpec.probeSelector
启用此设置后,你始终可以通过向它们添加 release: "rancher-monitoring" 标签来创建由 Cluster Prometheus 抓取的 ServiceMonitor 或 PodMonitor。在这种情况下,即使这些 ServiceMonitor 或 PodMonitor 所在的命名空间不是 System 命名空间,项目监控堆栈也会默认自动忽略它们。
如果你不希望用户能够在 Project 命名空间中创建聚合到 Cluster Prometheus 中的 ServiceMonitor 和 PodMonitor,你可以另外将 Chart 上的 namespaceSelectors 设置为仅目标 System 命名空间(必须包含 cattle-monitoring-system 和 cattle-dashboards,默认情况下资源通过 rancher-monitoring 部署到该命名空间中。你还需要监控 default 命名空间以获取 apiserver 指标,或创建自定义 ServiceMonitor 以抓取位于 default 命名空间中的 Service 的 apiserver 指标),从而限制你的 Cluster Prometheus 获取其他 Prometheus Operator CR。在这种情况下,建议设置 .Values.prometheus.prometheusSpec.ignoreNamespaceSelectors=true。这样,你可以定义能从 System 命名空间中监视非 System 命名空间的 ServiceMonitor。
提高 Cluster Prometheus 的 CPU/内存限制
根据集群的设置,我们一般建议为 Cluster Prometheus 配置大量的专用内存,以避免因内存不足的错误(OOMKilled)而重启。通常情况下,集群中创建的改动项(churn)会导致大量高基数指标在一个时间块内生成并被 Prometheus 引入,然后导致这些错误。这也是为什么默认的 Rancher Monitoring 堆栈希望能分配到大约 4GB 的 RAM 以在正常大小的集群中运行的原因之一。但是,如果你引入向同一个 Cluster Prometheus 发送 /federate 请求的项目监控堆栈,并且项目监控堆栈依赖于 Cluster Prometheus 的启动状态来在其命名空间上联合系统数据,那么你更加需要为 Cluster Prometheus 分配足够的 CPU/内存,以防止集群中的所有 Prometheus 项目出现数据间隙的中断。
我们没有 Cluster Prometheus 内存配置的具体建议,因为这完全取决于用户的设置(即遇到高改动率的可能性以及可能同时生成的指标的规模)。不同的设置通常有不同的推荐参数。
安装 Prometheus Federator 应用程序
- 点击 ☰ > 集群管理。
- 转到要安装 Prometheus Federator 的集群,然后单击 Explore。
- 点击应用 > Charts。
- 单击 Prometheus Federator Chart。
- 单击安装。
- 在元数据页面,点击下一步。
- 在命名空间 > 项目 Release 命名空间项目 ID 字段中,
System 项目是默认值,但你可以使用具有类似有限访问权限的另一个项目覆盖它。你可以在 local 上游集群中运行以下命令来找到项目 ID:
kubectl get projects -A -o custom-columns="NAMESPACE":.metadata.namespace,"ID":.metadata.name,"NAME":.spec.displayName
- 单击安装。
结果:Prometheus Federator 应用程序已部署在 cattle-monitoring-system 命名空间中。