Logging Architecture
This section summarizes the architecture of the Rancher logging application.
For more details about how the Logging operator works, see the official documentation.
Changes in Rancher v2.5
The following changes were introduced to logging in Rancher v2.5:
- The Logging operator now powers Rancher's logging solution in place of the former, in-house solution.
- Fluent Bit is now used to aggregate the logs, and Fluentd is used for filtering the messages and routing them to the
Outputs. Previously, only Fluentd was used. - Logging can be configured with a Kubernetes manifest, because logging now uses a Kubernetes operator with Custom Resource Definitions.
- We now support filtering logs.
- We now support writing logs to multiple
Outputs. - We now always collect Control Plane and etcd logs.
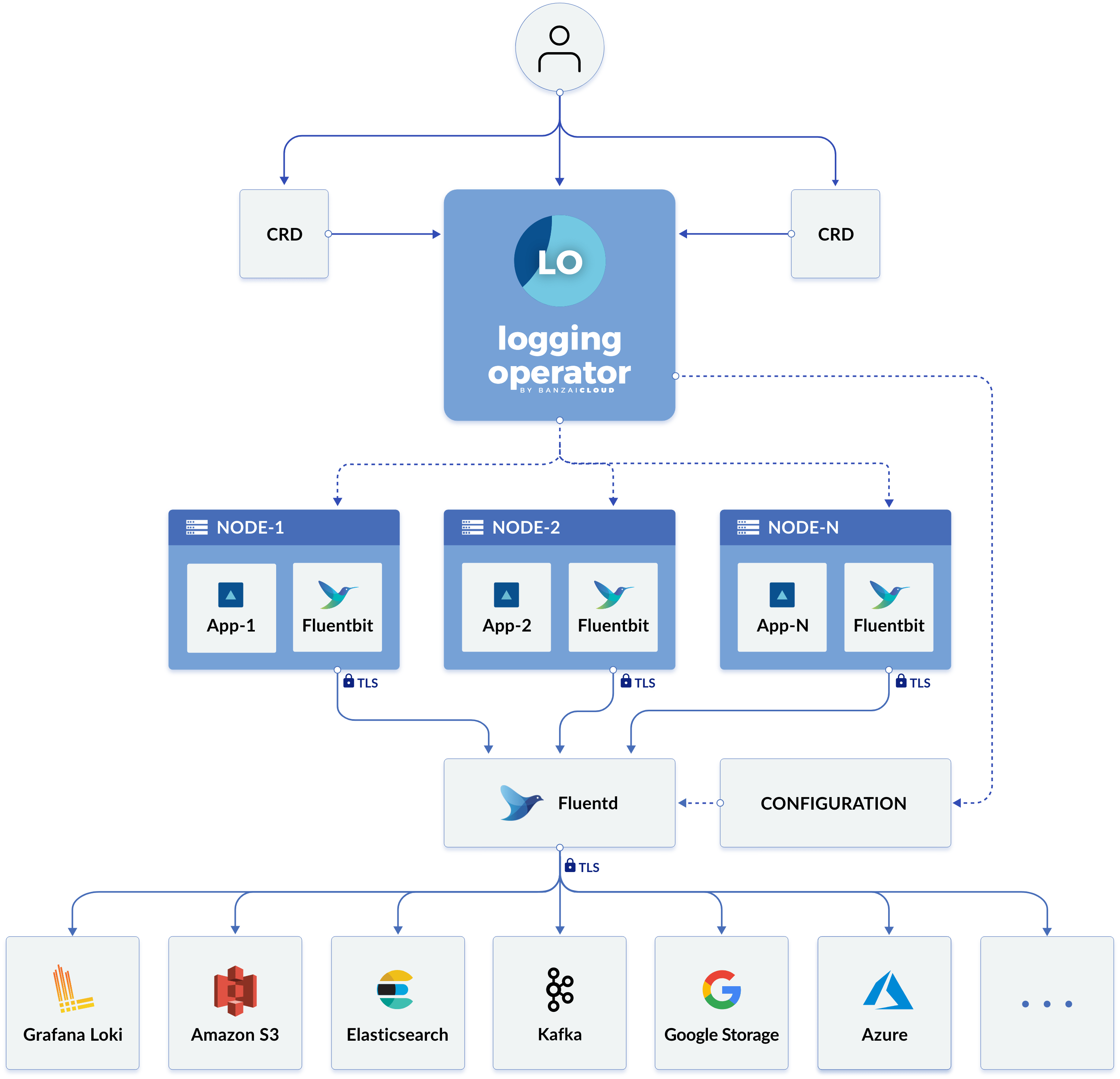
How the Logging Operator Works
The Logging operator automates the deployment and configuration of a Kubernetes logging pipeline. It deploys and configures a Fluent Bit DaemonSet on every node to collect container and application logs from the node file system.
Fluent Bit queries the Kubernetes API and enriches the logs with metadata about the pods, and transfers both the logs and the metadata to Fluentd. Fluentd receives, filters, and transfers logs to multiple Outputs.
The following custom resources are used to define how logs are filtered and sent to their Outputs:
- A
Flowis a namespaced custom resource that uses filters and selectors to route log messages to the appropriateOutputs. - A
ClusterFlowis used to route cluster-level log messages. - An
Outputis a namespaced resource that defines where the log messages are sent. - A
ClusterOutputdefines anOutputthat is available from allFlowsandClusterFlows.
Each Flow must reference an Output, and each ClusterFlow must reference a ClusterOutput.
The following figure from the Logging operator documentation shows the new logging architecture: