迁移到 Rancher 2.5+ Monitoring
如果你在 Rancher 2.5 之前启用了 Monitoring、Alerting 或 Notifiers,则无法自动升级到新的监控/告警解决方案。在 Cluster Explorer 中部署新的监控解决方案之前,你需要禁用并删除整个集群所有项目中的所有自定义告警、通知器和监控安装。
Rancher 2.5 之前的 Monitoring
从 2.2.0 开始,旧版 Rancher UI 中的全局视图允许用户在集群内独立启用 Monitoring & Alerting V1(均由 Prometheus Operator 提供支持)。
启用 Monitoring 后,Monitoring V1 会将 Prometheus 和 Grafana 部署到集群上,从而监控集群节点、Kubernetes 组件和软件部署的进程状态,并创建自定义仪表板来简化指标的可视化。
Monitoring V1 可以在集群级别和项目级别进行配置,并且会自动抓取 Rancher 集群上部署为应用的某些工作负载。
如果启用了 Alerts 或 Notifiers,Alerting V1 将 Prometheus Alertmanager 和一组 Rancher 控制器部署到集群上,允许用户定义告警并配置电子邮件、Slack、PagerDuty 等告警通知。用户可以根据需要监控的内容(例如系统服务、资源、CIS 扫描等)创建不同类型的告警。但是,只有在启用 Monitoring V1 时才能创建基于 PromQL 表达式的告警。
通过 Rancher 2.5 中的 Cluster Explorer 进行监控和告警
从 2.5.0 开始,Rancher 的 Cluster Explorer 允许用户在集群内同时启用 Monitoring & Alerting V2(均由 Prometheus Operator 提供支持)。
与 Monitoring & Alerting V1 不同,现在这两个功能都打包在此处的单个 Helm Chart 中。此 Chart 和可配置字段与 Prometheus 社区 Helm Chart kube-prometheus-stack 非常匹配,与上游 Chart 的任何偏差都可以在 CHANGELOG.md 中找到。
Monitoring V2 只能在集群级别进行配置。不再支持项目级别的监控和告警。
有关如何配置 Monitoring & Alerting V2 的更多信息,请参阅此页面。
RBAC 的更改
默认情况下,项目所有者和成员不再可以访问 Grafana 或 Prometheus。如果只读用户有权访问 Grafana,他们将能够查看任何命名空间的数据。对于 Kiali,任何用户都可以在任何命名空间中编辑不属于该用户的东西。
有关 rancher-monitoring 中 RBAC 的更多信息,请参阅此页面。
从 Monitoring V1 迁移到 Monitoring V2
虽然没有可用的自动迁移方案,但你可以手动将在 Monitoring V1 中创建的自定义 Grafana 仪表板和告警迁移到 Monitoring V2。
在安装 Monitoring V2 之前,你需要完全卸载 Monitoring V1。要卸载 Monitoring V1:
- 删除所有集群和项目特定的告警和告警组。
- 删除所有通知。
- 禁用集群 > 项目 > 工具 > Monitoring 下的所有项目监控安装。
- 确保所有项目中的所有项目监控应用都已删除,并且在几分钟后不会重新创建。
- 在集群 > 工具 > Monitoring 下禁用集群监控安装。
- 确保 System 项目中的 cluster-monitoring 应用和 monitoring-operator 应用已被删除,并且在几分钟后不会重新创建。
RKE 模板集群
要避免重新启用 Monitoring V1,请通过修改 RKE 模板 yaml 来禁用监控以及后续的 RKE 模板修订:
enable_cluster_alerting: false
enable_cluster_monitoring: false
迁移 Grafana 仪表板
你可以将在 Monitoring V1 中添加到 Grafana 的仪表板迁移到 Monitoring V2。在 Monitoring V1 中,你可以这样导出现有仪表板:
- 登录 Grafana
- 导航到要导出的仪表板
- 转到仪表板设置
- 复制 JSON 模型
在 JSON 模型中,将所有 datasource 字段从 RANCHER_MONITORING 更改为 Prometheus。你可以将所有出现的 "datasource": "RANCHER_MONITORING" 替换为 "datasource": "Prometheus"。
如果 Grafana 由持久卷支持,你可以将此 JSON 模型导入到 Monitoring V2 Grafana UI 中。
建议使用 cattle-dashboards 命名空间具有 grafana_dashboard: "1" 标签的 ConfigMap,来为 Grafana 提供仪表板:
apiVersion: v1
kind: ConfigMap
metadata:
name: custom-dashboard
namespace: cattle-dashboards
labels:
grafana_dashboard: "1"
data:
custom-dashboard.json: |
{
...
}
创建此 ConfigMap 后,仪表板将自动添加到 Grafana。
迁移告警
只有基于表达式的告警能直接迁移到 Monitoring V2。幸运的是,基于事件的告警可以设置为对系统组件、节点或工作负载事件的告警,而 Monitoring V2 中的告警已覆盖这些告警。所以没有必要迁移它们。
如果要迁移以下表达式告警:
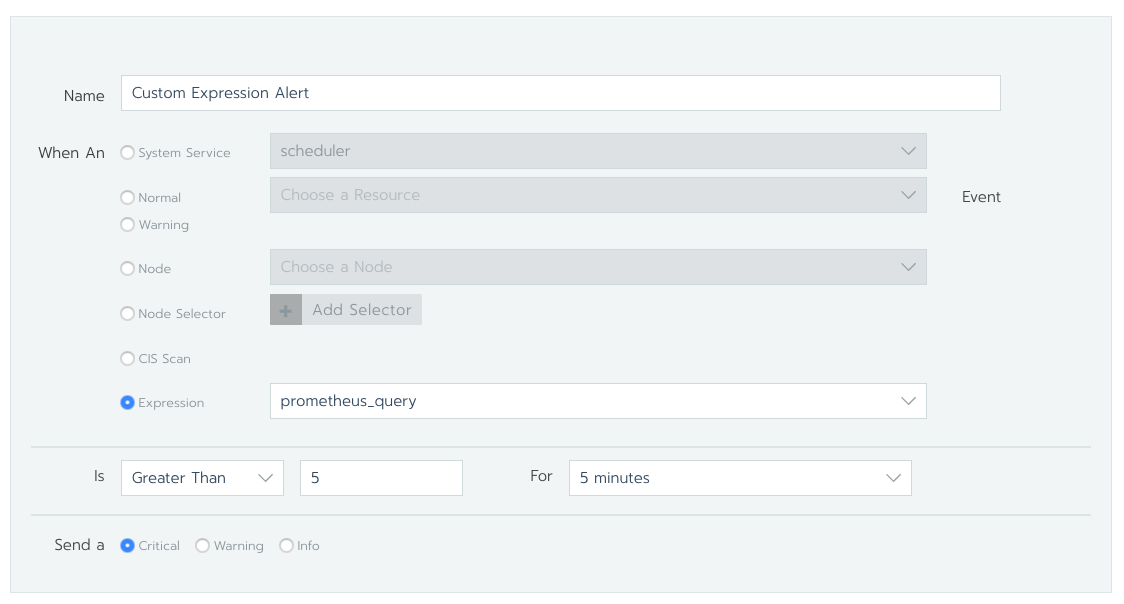
你必须在任意命名空间中创建如下 PrometheusRule 配置:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: custom-rules
namespace: default
spec:
groups:
- name: custom.rules
rules:
- alert: Custom Expression Alert
expr: prometheus_query > 5
for: 5m
labels:
severity: critical
annotations:
summary: "The result of prometheus_query has been larger than 5 for 5m. Current value {{ $value }}"
或通过 Cluster Explorer 添加 Prometheus Rule:
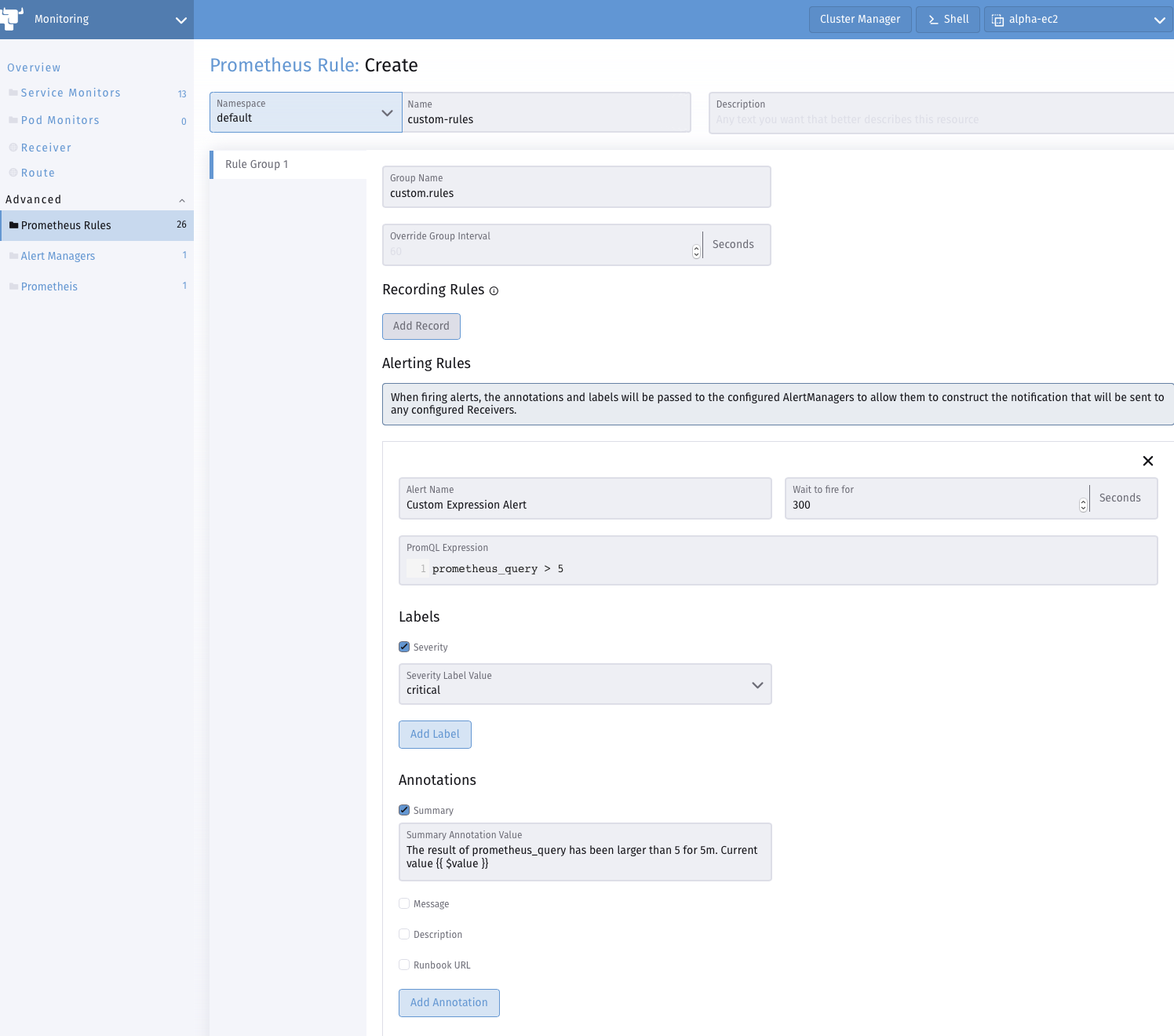
有关如何在 Monitoring V2 中配置 PrometheusRules 的更多详细信息,请参阅 Monitoring 配置。
迁移 Notifiers
Monitoring V1 中没有直接对应 Notifiers 的工作方式。相反,你必须使用 Monitoring V2 中的路由和接收器复制所需的设置。
为 RKE 模板用户迁移
如果集群是使用 RKE 模板管理的,你需要在后续的 RKE 模板修订版中禁用 Monitoring,以防止重新启用旧版 Monitoring。